

Il debutto travagliato di GPT‑5 e il “pasticcio” del router
Il nuovo GPT‑5 di OpenAI doveva essere un salto epocale, ma il suo lancio ha sollevato più critiche che applausi. Numerosi utenti hanno segnalato un netto passo indietro: risposte più lente, errori banali e una personalità “diluita” rispetto al vecchio GPT-4 (wired.com). Il colpevole? Un sistema di routing automatico pensato per gestire internamente più modelli, che al debutto si è inceppato. OpenAI aveva infatti introdotto un “router” intelligente in GPT‑5, capace di smistare le domande tra diversi motori (un modello rapido per compiti semplici, uno più profondo per quelli complessi). In teoria doveva migliorare efficienza e prestazioni instradando le richieste al modulo più adatto, risparmiando tempo e costi. In pratica, il sistema si è rotto al day-one, facendo sembrare GPT‑5 “più stupido” del predecessore.
Il CEO Sam Altman è dovuto intervenire in fretta: ha ammesso il problema, promesso correzioni al meccanismo di commutazione e persino introdotto un interruttore manuale per attivare una modalità “pensante” su richiesta degli utenti. L’episodio ha evidenziato con ironia la nuova frontiera (insidiosa) delle AI giganti: non basta avere più cervelli, bisogna anche saperli coordinare a dovere.
Router interni e Mixture-of-Experts: l’AI a “team di specialisti”
Come ci è arrivata OpenAI a mettere un router nel cuore di GPT‑5? Entra in gioco l’architettura Mixture-of-Experts (MoE), un approccio rivoluzionario per costruire modelli di intelligenza artificiale sempre più grandi in modo efficiente. Invece di un’unica rete neurale monolitica che fa tutto, un modello MoE è composto da tanti “esperti” specializzati in compiti diversi, orchestrati da un router intelligente (arsturn.comarsturn.com). Possiamo immaginarlo come un team di consulenti: ogni domanda posta al sistema viene analizzata dal router (una rete di gating) che decide a quali esperti inoltrarla, attivando solo quelli rilevanti e lasciando “a riposo” gli altri. Il vantaggio è duplice: da un lato si evita di far girare tutta la rete per ogni input (risparmiando enormi risorse computazionali), dall’altro ogni esperto può diventare veramente bravo in una “nicchia” (es. codice, logica, poesia) migliorando i risultati sul proprio dominio. Questa sparsità attivata permette di moltiplicare i parametri totali del modello (anche nell’ordine dei trilioni) senza crescere proporzionalmente in costi di calcolo (rohan-paul.com). Insomma, meno sprechi: un modello mastodontico, ma che accende solo i neuroni necessari al momento giusto.
Non sorprende che i MoE siano subito diventati la nuova frontiera dei modelli “top”. Google ha guidato la carica già nel 2021 col suo Switch Transformer da 1.6 trilioni di parametri, seguito da GLaM e altri, mostrando che gli MoE scalano efficacemente e battono i modelli densi equivalenti Si mormora persino che GPT‑4 “originale” sotto il cofano adottasse già una forma di MoE. GPT‑5 ha portato la scommessa all’estremo: invece di un singolo cervellone, è progettato come “un’unica mente” fatta in realtà di più menti, coordinate da un router ai limiti del fantascientifico. L’idea suona geniale: un router che funge da regista, assegnando compiti a un modello veloce e leggero per le richieste semplici, tirando in ballo un modulo “professore” più lento e profondo quando serve ragionare a fondo. Peccato che questo piccolo direttore d’orchestra software, nel debutto di GPT‑5, abbia mandato la sinfonia in confusione – un po’ come assumere un vigile per snellire il traffico e ritrovarsi invece con un ingorgo causato proprio da lui.
Schema semplificato di un sistema MoE: un router (in verde) smista i token di input verso diversi esperti (es: due Feed-Forward Network specializzate, FFN1 e FFN2) in base al contenuto.
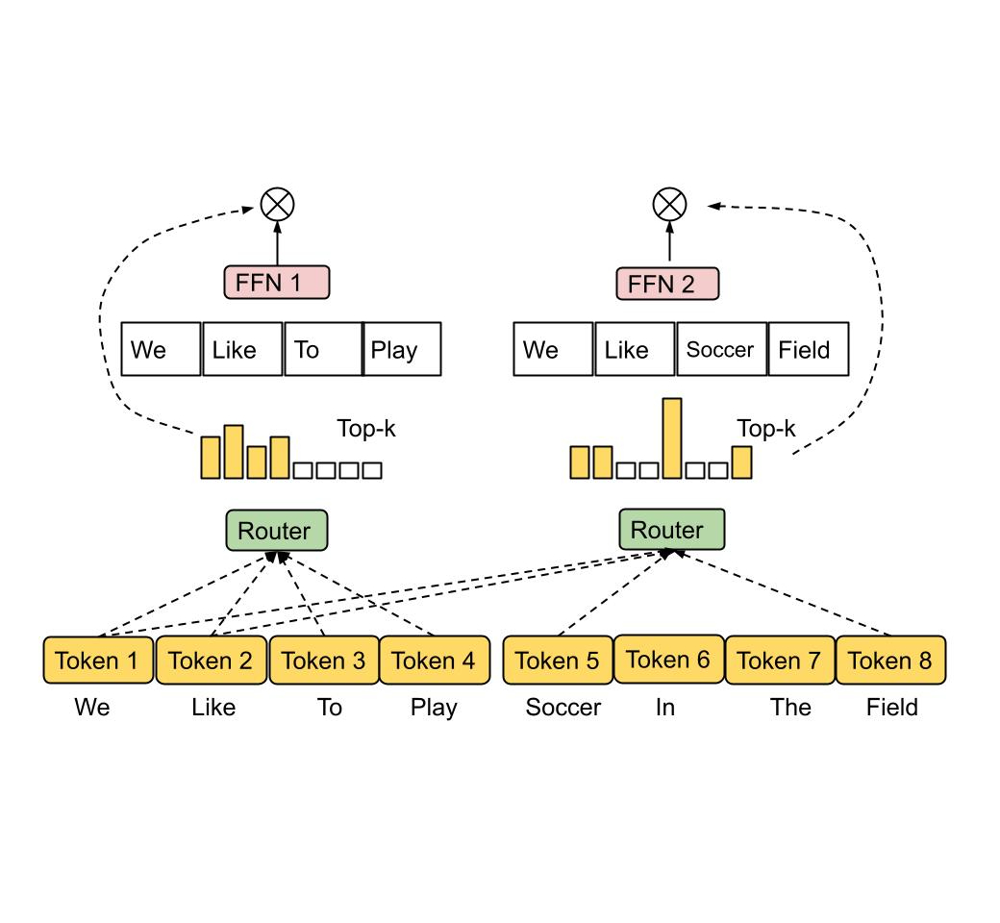
In questo esempio concettuale, la frase “We like to play” attiva percorsi differenti rispetto a “We like soccer field”, inviando le parole ai rispettivi esperti più adatti. Solo una frazione del modello viene attivata per ciascun input, rendendo il calcolo più efficiente. Un routing inefficace può però causare squilibri: alcuni esperti rischiano di rimanere sotto-utilizzati e “arrugginiti”, altri sovraccarichi e iper-specializzati – esattamente il tipo di problema visto in GPT‑5 al lancio.
Strategie di routing a confronto: dalla scelta del token agli esperti “in cerca di guai”
L’idea del router in un MoE è semplice, ma realizzarla in pratica è tutt’altro che banale. Negli ultimi anni i ricercatori hanno sperimentato diverse architetture di instradamento dei dati nei modelli a esperti. Ecco un elenco delle principali strategie emerse (ognuna con i suoi pro e contro):
- Routing tradizionale “Top-k” (scelta dal token): È l’approccio classico introdotto nei primi MoE moderni. Il router calcola per ogni token di input un punteggio di affinità verso ciascun esperto, poi ne sceglie i migliori, (ad esempio 1 o 2) attivandoli per quel token. In pratica, ogni parola/elaborazione “decide” a quali esperti rivolgersi. Questo metodo funziona ed è semplice, ma soffre di sbilanciamento: alcuni esperti finiscono col ricevere troppi token, altri quasi nessuno. Per evitare che qualche esperto vada in sovraccarico totale, i progettisti hanno dovuto introdurre complicati termini di loss ausiliaria per il bilanciamento (penalizzando il router se usa troppo un certo esperto). Anche così, la soluzione è imperfetta: spesso bisogna “sovradimensionare” la capacità di ogni esperto (anche 2-8× il carico teorico) per non perdere token per strada quando c’è troppa fila. Inoltre il numero di esperti attivati è fisso e non tiene conto della difficoltà del token: magari anche per parole semplici si attivano due esperti inutilmente, mentre un concetto ostico avrebbe bisogno del supporto di più di due esperti ma non può ottenerlo. Insomma, un sistema rigido che rischia di sprecare potenziale o, al contrario, di non darne abbastanza quando serve.
- Switch Transformer (routing Top-1 semplificato): Per aggirare parte della complessità, Google ha proposto con Switch Transformer (2021) un MoE dove il router seleziona un solo esperto per token (top-1) invece di due. Eliminando la combinazione di più esperti, si semplificano molto sia il training che l’infrastruttura di esecuzione: niente merging di output e meno rischio di overflow di buffer. Questo ha permesso di addestrare modelli con decine di esperti e oltre un trilione di parametri totali, con efficienza notevole. Il rovescio della medaglia è che limitare a un singolo esperto per volta può ridurre leggermente la qualità: il modello potrebbe non sfruttare appieno la varietà di competenze per input complessi. In altre parole, meno coordinazione, più semplicità, ma si rischia di tagliare con l’accetta situazioni dove servirebbe il contributo di più teste.
- Routing “Expert Choice” (scelta dall’esperto): Una svolta interessante è stata presentata da Google Brain nel 2022. Invece di far scegliere agli input gli esperti, si fa l’opposto: sono gli esperti che si propongono per elaborare i token. Ogni esperto ha un numero massimo di token che può accettare (la sua “capacità” per batch); il router allora assegna a ciascun esperto i token con i punteggi più alti per quell’esperto, garantendo che nessuno sfori il proprio buffer. Così si ottiene un bilanciamento perfetto: niente più esperti pigri o sovraccarichi, perché ognuno prende solo un certo numero di token e tutti lavorano. Un effetto collaterale positivo è che il numero di esperti per token diventa variabile: se un token è molto complesso/importante potrà comparire tra i top-k di diversi esperti (essendo elaborato da più reti in parallelo), mentre token banali forse verranno serviti da un solo esperto. Più flessibilità e miglior uso delle risorse insomma. I risultati? Il routing “Expert Choice” ha mostrato un training oltre 2 volte più veloce rispetto al gating tradizionale (top-1 e top-2) su modelli grandi, e una qualità superiore nei task di fine-tuning. Sembra la panacea, ma implementarla è più complesso: il router deve calcolare e ordinare le preferenze per esperto anziché per token, e richiede una gestione accurata dei buffer. Nonostante ciò, questa idea apre la strada a MoE più eterogenei e dinamici, in pieno spirito del progetto Pathways di Google.
- Router basato su LLM (esperto che smista esperti): Chi meglio di un modello linguistico può capire il contesto di una richiesta? Alcuni ricercatori hanno provato a far svolgere il ruolo di router a un mini-LM interno: in pratica un piccolo GPT che legge l’input e decide quali esperti attivare. Uno studio del 2025 (Liu & Lo) ha introdotto il framework LLMoE, usando proprio un modello linguistico pre-addestrato come router al posto del classico layer lineare. L’idea è che il router “intelligente” possa cogliere sfumature del contesto (es. riconoscere se una query finanziaria parla di azioni o criptovalute) e quindi scegliere gli esperti più adatti in modo più interpretabile. Nei test su compiti di trading finanziario questo approccio ha migliorato le performance, segno che infondere conoscenza del mondo nel routing può aiutare. Il rovescio della medaglia? Aggiunge ulteriore peso computazionale: far girare un modello aggiuntivo per ogni input può essere costoso, quindi va bilanciato il guadagno in qualità rispetto al costo. È un filone ancora sperimentale, ma indica quanto sia cruciale perfezionare il “cervello” che smista gli altri cervelli.
- Routing senza rete neurale (hashing, clustering): Una strada più radicale è eliminare del tutto l’apprendimento del router, sostituendolo con regole fisse. Alcuni lavori recenti hanno esplorato soluzioni come assegnare token ed esperti tramite funzioni hash o algoritmi di k-means clustering predefiniti. In pratica, l’allocazione dei token agli esperti avviene secondo criteri matematici o statistici (ad esempio in base al contenuto del token mappato a un codice hash), invece di farlo decidere a una rete addestrata. Questo approccio evita problemi di squilibrio dovuti a training sub-ottimale del router e riduce la complessità della fase di addestramento. Tuttavia, perdere la componente di apprendimento significa anche rinunciare a parte dell’ottimizzazione: un router statico non “impara” adattandosi ai dati, quindi potrebbe instradare in modo meno accurato soprattutto in compiti molto complessi o sfumati. Al momento queste tecniche sono più che altro oggetto di ricerca sperimentale; la loro utilità pratica resta da dimostrare, ma sono interessanti tentativi per aggirare il collo di bottiglia del routing neurale.
- Architetture ibride e multi-livello: Oltre alle strategie di routing in sé, c’è fermento nell’integrare MoE con altre innovazioni architetturali. Ad esempio, il modello Jamba (2024) ha combinato strati Transformer standard con “strati Mamba” (un modulo di memoria esterna) intervallati da livelli MoE. Questo design ibrido ha prodotto un modello in grado di gestire contesti lunghissimi (fino a 256k token) su un singolo GPU da 80GB, dimostrando che gli esperti possono convivere con meccanismi di memoria per estendere le capacità in direzioni nuove. Un altro esempio è OLMoE-1B-7B (2024): un modello open-source da 7 miliardi di parametri totali, di cui però solo 1 miliardo attivi per token grazie al MoE. Gli autori di OLMoE hanno osservato che gli esperti imparano davvero specializzazioni distinte (hanno misurato nuove metriche di diversità del routing), confermando empiricamente che un MoE ben progettato ripartisce la conoscenza tra gli esperti in modo significativo. Infine, per scalare a dimensioni estreme, si sperimentano MoE gerarchici. Il recente modello DeepSeek-V3 (2024) ha raggiunto la cifra vertiginosa di 671 miliardi di parametri totali adottando un design a più livelli di esperti annidati. Sorprendentemente, con le giuste tecniche di ottimizzazione, sono riusciti ad addestrarlo su 14.8 trilioni di token senza instabilità né “esperti che impazziscono” lungo il percorso. Questi esempi ibridi e gerarchici mostrano che il concetto di MoE è flessibile: si può inserire a vari livelli di un modello e combinarlo con altre idee per spingere ancora più in là la frontiera dell’AI.
Limiti e sfide aperte dei router MoE
Per quanto promettenti, i sistemi a esperti con router incorporato non sono una bacchetta magica – come la stessa vicenda di GPT‑5 ci ha insegnato. Ci sono sfide aperte e limiti noti che i ricercatori stanno cercando di superare:
- Instabilità e “collasso” degli esperti: Addestrare decine di esperti in parallelo richiede un equilibrio delicato. Se il routing è imparato male, alcuni esperti potrebbero ricevere così pochi dati da non riuscire a specializzarsi (restando “indietro” in apprendimento), mentre altri diventano fin troppo specializzati perché usati in eccesso. Questo squilibrio può portare a collapse mode, dove in pratica il modello spreca capacità su esperti inutilizzati o ridondanti. Le tecniche di bilanciamento (loss ausiliarie, capacity factor, ecc.) mitigano il problema ma non lo eliminano del tutto. Ogni nuovo algoritmo di routing – come abbiamo visto – cerca infatti di migliorare la distribuzione del carico, segno che il problema è sentito.
- Costo computazionale nascosto: Attivare solo pochi esperti per token rende l’inferenza più leggera, ma attenzione ai costi aggiuntivi “dietro le quinte”. Il router stesso è uno strato neurale extra che va eseguito; inoltre distribuire i dati ai vari esperti può implicare operazioni di comunicazione pesanti tra GPU/TPU. In GPT‑5, ad esempio, parte della lentezza iniziale era dovuta proprio al sistema di routing che sceglieva modelli più lenti anche quando non serviva, aggiungendo latenza. L’ottimizzazione di questi “overhead” è cruciale: un MoE mal progettato rischia di essere efficiente sulla carta, ma inefficiente all’atto pratico se il router e la gestione del traffico divorano i guadagni di sparseness.
- Complessità di implementazione e debugging: Un modello MoE con router è significativamente più complesso di un modello standard. Ci sono più componenti che possono fallire: il gating, la sincronizzazione dei thread tra esperti, la gestione della memoria per buffer variabili, ecc. Il fiasco iniziale di GPT‑5 lo ha mostrato in modo eclatante – un piccolo bug nel meccanismo di switch ha degradato l’intero sistema. Inoltre, diagnosticare i problemi non è banale: se un output di scarsa qualità è dovuto a un parametro dell’esperto o al router che ha selezionato l’esperto sbagliato? Questa opacità rende più difficile affinare e fidarsi di tali modelli. Serve molta cura (e spesso trial-and-error) per far convivere tanti “sottomodelli” senza che si pestino i piedi a vicenda.
- Adattamento ai contesti e prompt adversariali: Un router automatico potrebbe essere ingannato o portato fuori strada da input formulati ad arte. Alcuni utenti hanno notato, ad esempio, che GPT‑5 inizialmente attivava la sua modalità “riflessiva” solo se rilevava frasi chiave come “think hard”, altrimenti restava su quella semplice Questo significa che un prompt potrebbe aggirare il routing – volontariamente o meno – ottenendo una modalità di ragionamento non ideale. OpenAI ha dovuto addirittura fornire un comando esplicito per forzare la modalità più potente, segno che automatizzare al 100% l’instradamento resta problematico. Inoltre, la presenza di un router introduce un nuovo vettore di attacco: prompt maligni potrebbero mirare a confondere il gating (per esempio, far attivare deliberatamente l’esperto sbagliato) come forma di prompt injection avanzata. È un territorio inesplorato sulla sicurezza dei LLM, che richiederà attenzione man mano che i MoE diverranno più comuni.
In sintesi, i router interni aprono possibilità incredibili ma aggiungono strati di complessità su cui stiamo ancora imparando. La vicenda di GPT‑5 – tra ironia e frustrazione – lo dimostra: anche un colosso AI può inciampare su un dettaglio architetturale e trasformare un modello rivoluzionario in un mezzo fiasco temporaneo.
Il futuro (incerto) dei “vigili” dell’AI
Viene da chiedersi: dopo il caos iniziale, i router MoE rappresentano davvero il futuro delle AI gigantesche? Oppure sono un’astuta misura di risparmio spacciata per innovazione? Alcuni critici hanno sostenuto che GPT‑5, con la sua architettura a esperti, sia in realtà un modo per tagliare costi e servire più utenti scaricando le richieste semplici su modelli economici, più che un vero salto in capacità cognitiva. La verità probabilmente sta nel mezzo. I progressi scientifici degli ultimi due anni indicano chiaramente che le Mixture-of-Experts funzionano e consentono di scalare modelli altrimenti irrealizzabili. OpenAI stessa sembra crederci: ha persino rilasciato versioni open-source con architettura MoE (gpt-oss-120B e 20B) per la comunità, segno che punta su questo paradigma. Tuttavia, come ogni tecnologia giovane, c’è una curva di maturazione da percorrere – fatta di tentativi, errori e migliorie iterative.
Forse un giorno ricorderemo il router di GPT‑5 come una lezione necessaria: il momento in cui abbiamo capito che orchestrare una folla di reti neurali è tanto importante quanto addestrare le singole reti. In fondo, anche nel mondo umano un team di geni può fallire miseramente senza una buona leadership. Nel frattempo, la prossima volta che il tuo chatbot “super-intelligente” darà una risposta sciocca, non arrabbiarti troppo con lui: potrebbe semplicemente aver preso un’uscita sbagliata nell’instradatore mentre cercava l’esperto giusto. In altre parole, l’AI del futuro sarà pure un collettivo di menti brillanti – ma persino le menti brillanti possono perdersi, se Google Maps (o meglio, il router) le manda fuori rotta. E chissà, magari la vera intelligenza artificiale generale inizierà a emergere proprio quando riusciremo a costruire router così furbi da non farci rimpiangere i vecchi modelli “tuttofare”. Fino ad allora, prepariamoci a qualche altro intoppo: la strada verso il futuro dell’AI è disseminata di snodi critici, e imboccarli tutti correttamente al primo colpo è una sfida degna di… beh, di un GPT-6 con un router finalmente all’altezza delle promesse.